XIRL: Cross-embodiment Inverse Reinforcement Learning
Conference on Robot Learning (CoRL) 2021
Abstract. We investigate the visual cross-embodiment imitation setting, in which agents learn policies from videos of other agents (such as humans) demonstrating the same task, but with stark differences in their embodiments -- shape, actions, end-effector dynamics, etc. In this work, we demonstrate that it is possible to automatically discover and learn vision-based reward functions from cross-embodiment demonstration videos that are robust to these differences. Specifically, we present a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle-consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences. Prior to our work, producing rewards from self-supervised embeddings typically required alignment with a reference trajectory, which may be difficult to acquire under stark embodiment differences. We show empirically that if the embeddings are aware of task progress, simply taking the negative distance between the current state and goal state in the learned embedding space is useful as a reward for training policies with reinforcement learning. We find our learned reward function not only works for embodiments seen during training, but also generalizes to entirely new embodiments. Additionally, when transferring real-world human demonstrations to a simulated robot, we find that XIRL is more sample efficient than current best methods.
Method

Paper
★ Best Paper Award Finalist ★
Conference on Robot Learning (CoRL) 2021
Latest version (Sept. 2021): arXiv:2106.03911 [cs.RO]
OpenReview submission: here

The official code is available on Github. It includes:
We're also releasing the following datasets:
Team






{kind=link}
1 Robotics at Google 2 Stanford University 3 UC Berkeley
X-MAGICAL Benchmark
We introduce a benchmark extension of MAGICAL, called x-MAGICAL, specifically geared towards cross-embodiment imitation. The goal of X-MAGICAL is to test how well imitation or reward learning techniques can adapt to systematic embodiment gaps between the demonstrator and the learner. For example, in the Sweeping task, some agents can sweep all debris in one motion while others need to sweep them one at a time. These differences in execution speeds and state-action trajectories pose challenges for current LfD techniques, and the ability to generalize across embodiments is precisely what this benchmark evaluates.
Gripper
Longstick
Mediumstick
Shortstick
X-REAL Dataset
We collect a real-world dataset named X-REAL (Cross-embodiment Real-world demonstrations), which contains 93 demonstration videos of different embodiments (manifested as different manipulator end-effectors) solving the same manipulation task in the real-world: transferring five pens to two cups consecutively. This is a multi-step manipulation task where the pens on the table need to be lifted to one cup and then moved again to a separate cup. The different end-effectors consist in a human hand as well as 6 tools purchased from Amazon. We showcase some of the embodiments below.
One Hand Five Fingers
One Hand Two Fingers
Two Hands Two Fingers
RMS Grabber
Tongs
Irwin Quick-Grip
Qualitative Results
XIRL Reward Visualization

Positive demo

Negative demo

Overshoot demo
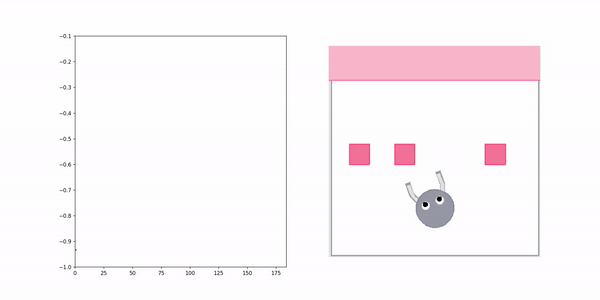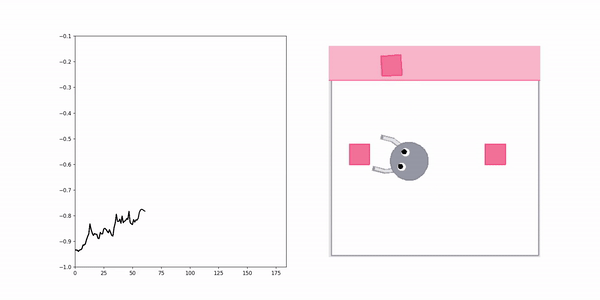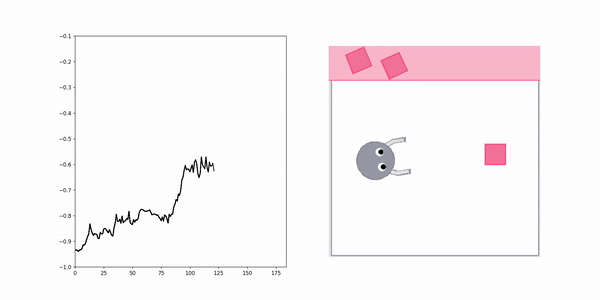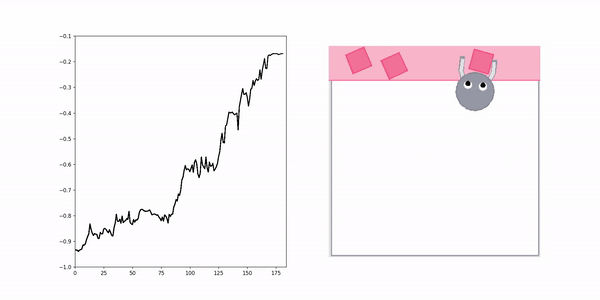
Positive demo
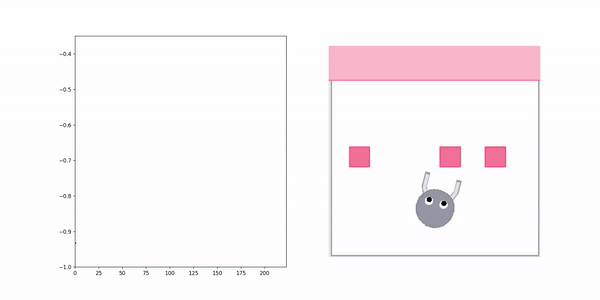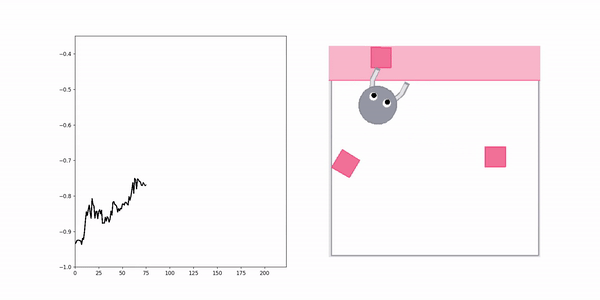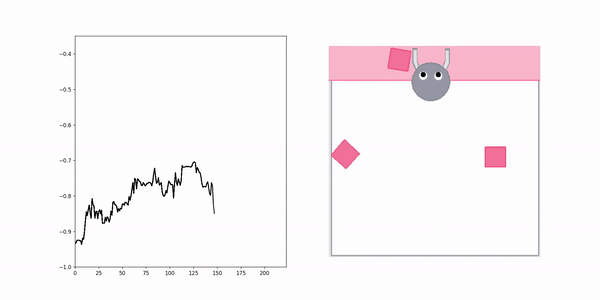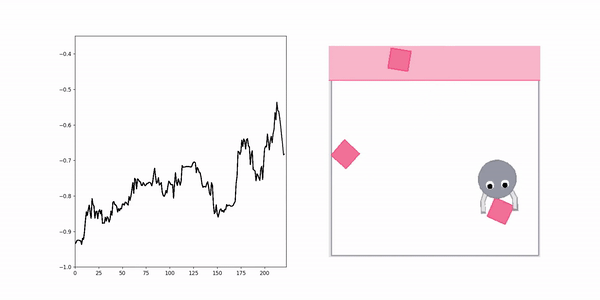
Negative demo
t-SNE Projection
We visualize the t-SNE projection of four demonstrations in simulation on an X-MAGICAL embodiment, and in the real-world. In each video below, the frame border color corresponds to the trajectory color in the middle plot and the highlighted marker denotes the current frame’s embedding.
Citation
@article{zakka2021xirl,
title = {XIRL: Cross-embodiment Inverse Reinforcement Learning},
author = {Zakka, Kevin and Zeng, Andy and Florence, Pete and Tompson, Jonathan and Bohg, Jeannette and Dwibedi, Debidatta},
journal = {Conference on Robot Learning (CoRL)},
year = {2021}
}
Acknowledgements
We would like to thank Alex Nichol, Nick Hynes, Sean Kirmani, Brent Yi and Jimmy Wu for fruitful technical discussions, Sam Toyer for invaluable help with setting up the simulated benchmark, and Karl Schmeckpeper for discussions and help related to RLV.
If you have any questions, please feel free to contact Kevin Zakka.